Gravwell's ingesters can pull data from a wide variety of sources and we advocate keeping raw data formats for root cause analysis, but sometimes it's nice to massage the data a little before sending it to the indexers. Maybe you're getting JSON data sent over syslog and would like to strip out the syslog headers. Maybe you're getting gzip-compressed data from an Apache Kafka stream. Maybe you'd like to be able to route entries to different tags based on the contents of the entries. Gravwell's ingest preprocessors make this possible by inserting one or more processing steps before an entry is sent upstream to the indexer.
The Preprocessor Architecture
An ingester reads raw data from some source (a file, a network connection, an Amazon Kinesis stream, etc.) and splits that incoming data stream out into individual entries. Before those entries are sent to a Gravwell indexer, they may optionally be passed through an arbitrary number of preprocessors as shown in the diagram below.
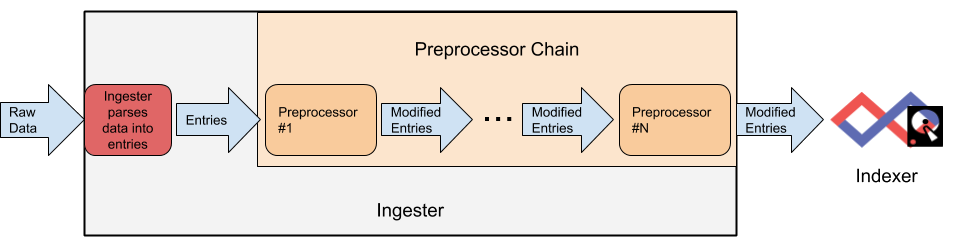
Each preprocessor will have the opportunity to modify the entries. The preprocessors will always be applied in the same order, meaning you could e.g. uncompress the entry's data, then modify the entry tag based on the uncompressed data.
The following ingesters support preprocessors as of Gravwell 3.3.7:
- Simple Relay
- Kinesis
- Kafka
- Google PubSub
- Office 365
- HTTP
Preprocessors are configured in each ingester's config file, then attached to the data consumers defined within that file. It's much easier to demonstrate than to try to explain, so let's look at an example!
Keybase Chatlogs
At Gravwell, we use Keybase for work chat and for real-time customer support of Community Edition users. One neat feature of Keybase is that you can export the messages from a given channel as JSON. It would be interesting to import all the messages from a Keybase channel into Gravwell for analysis, so let's try it.
First, we use the `list-channels` command to find the conversation ID of our gravwell.community channel:
$ keybase chat list-channels -json gravwell.community
{"convs":[{"convID":"0000[...]cb2","tlfID":"3b8c[...]a525","topicType":1,
"isPublic":false,"isEmpty":false,"isDefaultConv":true,
"name":"gravwell.community",
"snippet":"traetox: If you can point me to anything that describes exporting
and outputs we could help rig up an ingester to eat those feeds",
"snippetDecoration":0,"channel":"general", [...] }
We then use the "convID" field in that response to send another request, which dumps the conversation to a file:
keybase chat api -m '{ "method": "read", "params": { "options": { "conversation_id": "0000c136a95045de46f7b8ee5d16fcffc485eec4065b416c7ccf14836315fcb2" } } }' > /tmp/gravwellcommunity.json
However, when we pretty-print the file and look at it, we see that it consists of one giant JSON structure, with all the messages in an array inside it:
{
"result": {
"messages": [
{
"msg": {
"id": 1334,
"conversation_id": "0000[...]cb2",
"channel": {
"name": "gravwell.community",
"members_type": "team",
"topic_type": "chat",
"topic_name": "general"
},
[...]
"unread": false,
"channel_mention": "none"
}
},
{
"msg": {
"id": 1333,
"conversation_id": "0000[...]cb2",
"channel": {
"name": "gravwell.community",
"members_type": "team",
"topic_type": "chat",
"topic_name": "general"
},
"sender": {
[...]
}
If we tried to ingest this as-is, we'd just end up with one single, giant entry! It would be difficult to analyze this:
Now, we can use a preprocessor to split it into separate entries. We'll set up a listener with the Simple Relay ingester to accept the raw data, then apply a preprocessor to the entry. Here's the relevant snippet from simple_relay.conf:
[Listener "keybase"]
Bind-String="0.0.0.0:7778"
Tag-Name=keybase
Preprocessor="jsonsplit"
[Preprocessor "jsonsplit"]
Type=jsonarraysplit
Extraction="result.messages"
This establishes a network listener on port 7778 that treats each line as its own entry. The Listener specifies that we should apply the preprocessor config named "jsonsplit". This is set up to use the "jsonarraysplit" preprocessor module, which takes a JSON array and splits each element of the array into its own entry. The parameter Extraction="result.messages" simply tells it where to find the array in the JSON.
With this configuration in place, we use netcat to send the contents of the file to the Simple Relay listener (cat /tmp/gravwellcommunity.json | nc localhost 7778). At first, it seems like the entries haven't been ingested--but then I search over a wide range, including the future, and find them in July of 2020:
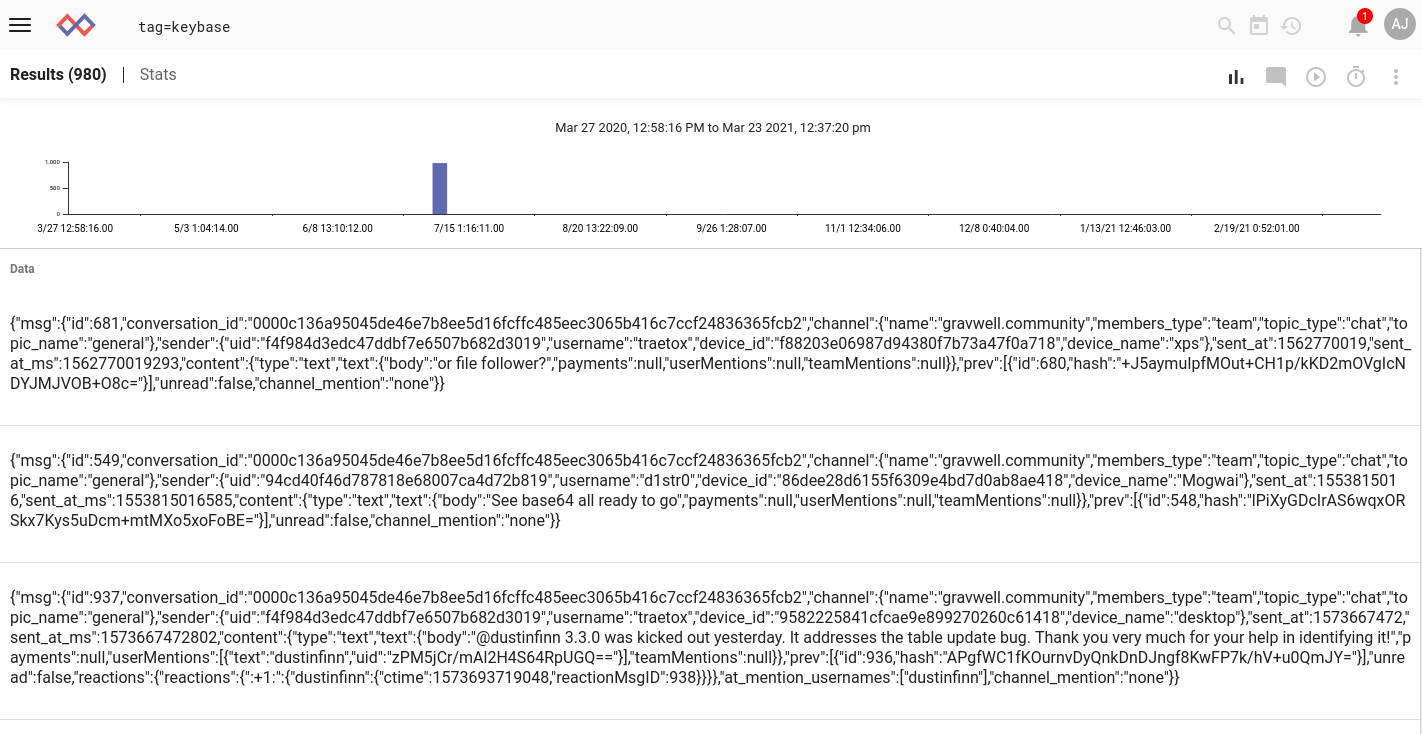
The chat messages have been appropriately split up, but they all have the same wrong timestamp. The reason is simple: the ingester attempted to extract a timestamp from that one giant line, and while it found something which could be parsed into a valid timestamp, it wasn't the correct timestamp. Then when the jsonarraysplit module split it up into many entries, it just kept using the same wrong timestamp on each new entry.
Gravwell has another preprocessor module which can extract timestamps based on a regular expression, and because we can stack preprocessors we can apply that module to every entry that comes out of the JSON array splitting preprocessor. We simply define another preprocessor in the config file and add it to the Listener after jsonsplit:
[Listener "keybase"]
Bind-String="0.0.0.0:7778"
Tag-Name=keybase
Preprocessor=jsonsplit
Preprocessor=ts
[Preprocessor "jsonsplit"]
Type=jsonarraysplit
Extraction=result.messages
[Preprocessor "ts"]
Type=regextimestamp
Regex ="sent_at_ms\":(?P<mstimestamp>\\d{13,18},)"
TS-Match-Name=mstimestamp
Using the regextimestamp preprocessor module, we define a regular expression which will pull out the contents of the "sent_at_ms" field from each JSON message. This field represents the number of milliseconds since the Unix epoch, which the preprocessor then knows how to parse.
With that in place, we restart the ingester and re-send the file. Doing a search over the last three months, we see messages scattered throughout the time period, as they should be:

Now we can start having fun, like analyzing which time of day sees the most chat traffic. We use the new `time` module to get the hour from each timestamp, then chart the counts over the last three months:
tag=keybase time -f "15" TIMESTAMP hour
| count by hour
| chart count by hour limit 100
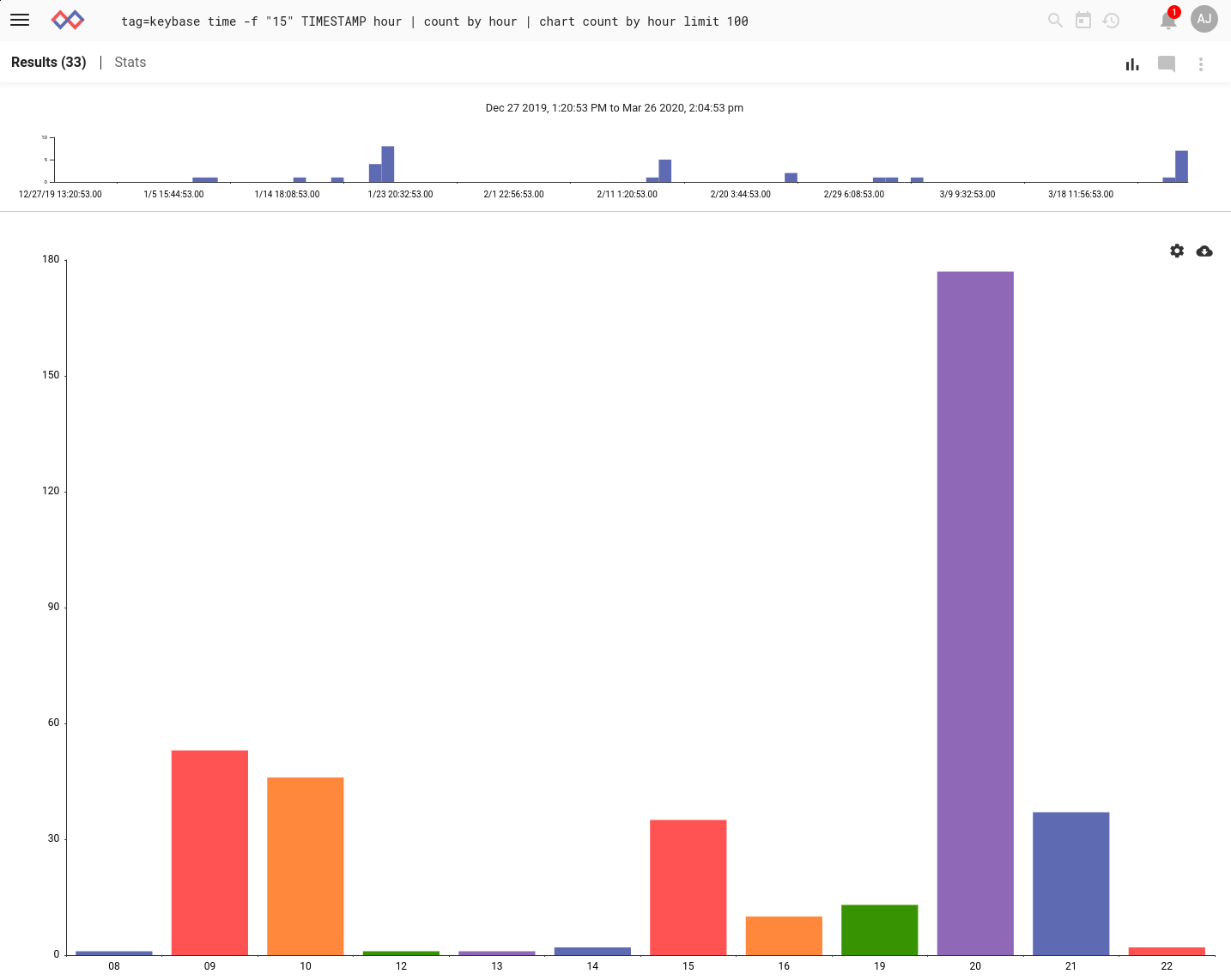
Looks like most of the chatter happens at 8 PM Mountain time, with another burst in the morning. This makes sense, considering that a lot of Community Edition users are experimenting at home and will be asking questions after work!
Conclusion
We've only touched on two of the available preprocessors in this blog post, and only for a specific use case. You can find more detailed information on all the preprocessors available, with instructions on configuring each of them, on our preprocessor documentation page.
As always, feel free to email sales@gravwell.io if you want to learn more about Gravwell, or hit the button below to sign up for a free Trial license. Thanks for reading!
